
Homestuck's Alchemy IN THREE D! (...still sucks because SV3D is garbage!)
A quick update/exposé, feel free to ignore this if you only read this blog for the reviews

Hey there, just a quick update to my continuing experiments in item alchemy. You can see an explanation of what I’m trying to do in the previous article, so go read that if you haven’t:
How I Cracked Homestuck's Alchemy with Stable Diffusion and GPT-4

We’re finally achieving what Homestuck fans tried to do for over a decade. For real. Keep reading for an obnoxiously technical primer on how to do SBURB Alchemy at home. This is technically part 2 of a loose series on generative AI, so read the first article afterwards if you’re interested.
Three days ago, Stability AI (the company known for Stable Diffusion, the most famous open source image generation model) released a press release on their BRAND NEW 3D MODEL.

They even accompanied it with a futuristic video showing decently textured models1, all made from a single photo of an object. Note how small the object is compared to the full size of the image. This will become relevant later.
Normal people were like “oh, neat” and forgot about it instantly. I only realized how improved my alchemy system would be by adding this into the mix.
Just imagine. An alchemiter with a 3D model spinning above it. You don’t need to imagine, actually. I made this concept image that’s almost as good as the one above in order to show why this is extremely important:

You read my last article, right? I used AUTOMATIC1111’s web UI for diffusion models, which is just a big dashboard where you have to do all actions by hand. The generative AI world has mostly moved on from things like that. It’s all visual workflows now.

You’re basically linking workflows together in assembly line fashion. Generate an image with x parameters, get the output from that, remove the background, get the mask, use that mask to generate another image… things like that.
Well, I found one for trying out SV3D in ComfyUI.2 I’ll try to keep the article body short but make heavy use of footnotes for those who want to replicate my experiment.
We need the following building blocks to make this work:
The video/3D model: that’s Stable Video 3D.3
ComfyUI adapter blocks for video models, which aren’t installed by default yet (I think).4
The 2D model: since we want to replicate alchemy, which takes text input, you’ll need a way to turn text into the single image we’ll feed into the video model. I used Ultraspice (XLTURBO),5 because I wanted a model based on Stable Diffusion XL Turbo and that was the first I saw recommended. Ideally you’ll use Stable Diffusion 3 whenever that comes out.
Positive word suffixes: to whatever we want to generate, I add “blank background, white background, thumbnail, sale, buy, preview, Amazon, checkout”, because without a solid color background, the 3D model will freak out.
Negative word suffixes: “bad hands, text, watermark”, because this is an experiment and I didn’t want to think too much.
A ComfyUI workflow: I started from the workflow Some Guy used, but that was only “input an image manually and turn it into video”. I wanted text input, so I modified it.6
Once everything is connected, it looks like this:

It looks complicated, but most of it you’ll only have to set up once or you don’t ever need to understand:7
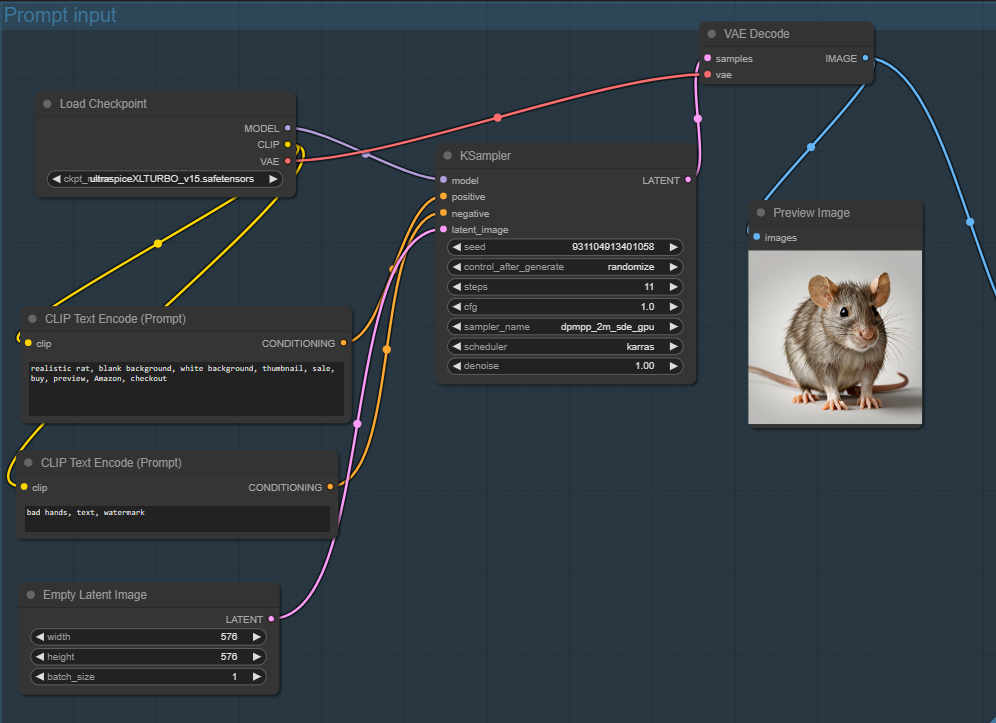
CLIP Text Encode is just how we feed the positive and negative prompts.
KSampler takes the prompts and a “latent image” to provide settings to the model. The settings will vary based on the image model you use here, but these were the recommended ones for Ultraspice.
VAE Decode generates the image itself and previews it + sends it away.
Then we get to the video steps.
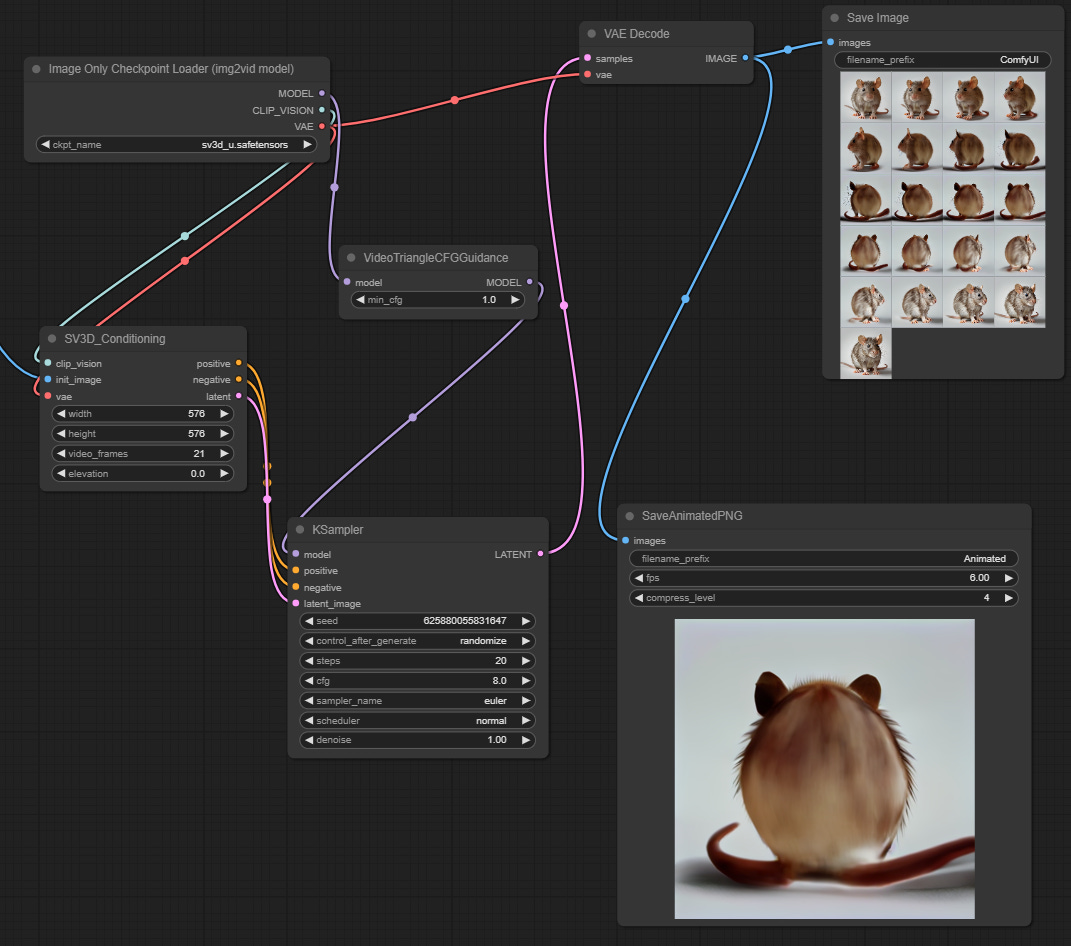
The input is “init_image”, the image that we generate in the other step.
The rest is similar, but there’s an intermediate VideoTriangleCFGGuidance block between image model and sampler which, uh… does something. Guides triangles?8
We save the output as frames (optional) and as animated PNG (it’s either this or animated WEBP, and yes, both fucking suck).

This process took a bit of trial and error. Here are a couple steps where I fucked up. First, when I used Some Guy’s Euler values for the KSampler instead of the appropriate ones for my model:

Or when the CFG scale was too high, which gives bad AI images their classic glossy, high contrast feel. I had video generation working by now, but the gloss made it think it was a flat image.

Or when I tried to generate an image larger than 576 pixels wide. This was my first hint that Stable Video 3D is a piece of shit.

But eventually I figured out the Proper Workflow.9 Even then, there were clear issues.

As you can see, the first frame that was the image input looks like, ten times better and higher resolution until the moment it begins turning. Additionally, the AI tends to cheat hard and turn textures black when it’s time to invent them.
It tends to “flatten” any object it does not recognize as 3D, which is fair, but leads to some silly outputs.

The model was trained on simple backgrounds. It will absolutely shit itself if you feed in an image with a complex one.

And finally, even when all stars align… it’s just kind of bad?




The results look so awful (if charming) that I am formally accusing the SD team of cherry-picking. I mean, every AI team does it, but someone has to make them face accountabili— wait, you’re telling me Stability AI is suddenly bleeding developers all over the place as of yesterday? I guess that’s enough punishment.
I didn’t even get to the point of turning the workflow into an API endpoint to call it with custom user input, like I did last article.
There’s just no benefit to doing it. It adds at least one minute10 to the image generation process, it’s not a very smart model, it’s low resolution, and requires many background-removing manual steps before it can become useful.
It was fun to generate endless 3D huskies, though, and I hope seeing the process was fun to you. Thank god for that doggy face carrying me through these experiments.
Yes, it’s confusing that “model” is used with two different meanings here.
You can get ComfyUI from GitHub here: https://github.com/comfyanonymous/ComfyUI. You’ll see an “easy installation method” for Windows, but I used the manual installation, because I suspected the former might lock me into a “stable” version that doesn’t have the features required for SV3D yet. Feel free to use either, maybe it’ll work for you.
You can download the weights from HuggingFace: https://huggingface.co/stabilityai/sv3d and put them in your models/checkpoints folder. We only want the “_u” version, its .safetensors file, since we only care about one camera angle and we’re not going to input a video.
I’m sorry, but you’ll need a HuggingFace account, and for some reason you’ll also need to do this:
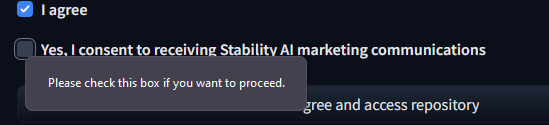
Get them from here https://github.com/kijai/ComfyUI-KJNodes and clone them into your custom_nodes folder as it says.
Get it from here https://civitai.com/models/229392/ultraspice-xlturbo and put it in your models/checkpoints folder.
The video is https://www.youtube.com/watch?v=fffHFjUTUn0, and I followed some other instructions from https://www.reddit.com/r/comfyui/comments/1bijagf/sv3d_model_is_here_img_video/, but you shouldn’t need them. I did need to use Chrome, for some reason, Firefox hates ComfyUI.
Values like steps and cfg often require fiddling with random numbers until “it looks right”, instead of being based on any formula. Even OpenAI does shit like this with their hyperparameters. Most generative AI is like this when you get down to brass tacks.
Look, it’s more science art than an art science.
Adding the 20 minutes that it takes to initially load the models into my RTX 3070 graphics card. This only applies to the first image generated after a restart, though.
Thanks for the review. Yes, after installing the model in ComfyUi, I'm struggling to see its use value, at least in its current version. All my attempts were either blurry, very blocky and pixelated, or totally freakish and chaotic if I tried over the 576 resolution. Still, the fact that we're even anywhere near being able to do this still amazes me. I'm sure after the public release of SORA these developments will either up their game or be abandoned.